
티스토리 뷰
Ceph란?
확장가능하고 open된 SDS(Software Defined Storage) 플랫폼이다.
신뢰성, 확장성, 고성능을 제공하게 설계된 분산 데이터 객체 저장소이다.
비정형데이터를 수용하고 현대의 인터페이스 및 레거시 인터페이스를 동시에 지원할 수 있다.
Unified Storage로 이야기하고 있으며 이에 다음과 같은 연결성을 제공한다.
- native language interface (C/C++, python, java ..)
- RESTful interface (AKA, Object Storage)
- Block device interface (AKA, Block Storage)
- Filesystem interface (AKA, File Storage)
Architecture
기본 architecture는 다음과 같다.
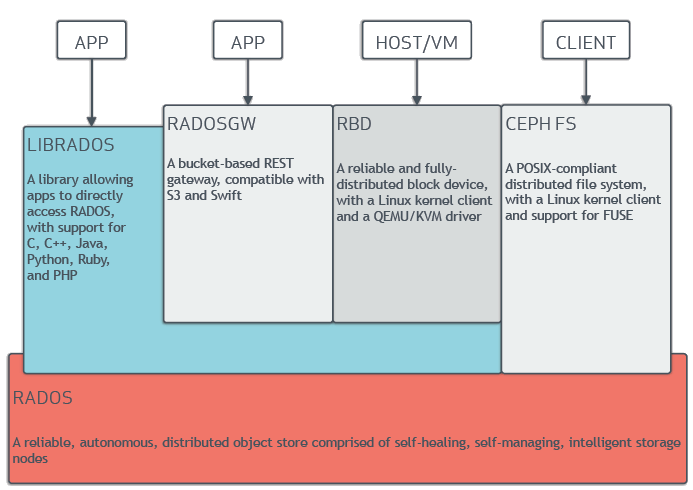
어떤 client 방식이든 RADOS Layer 를 거쳐 object 방식으로 저장되게 된다.
object든 block 방식이든 마지막에는 RADOS Layer에 의해 object로 저장되게 된다.
- NO SPOF
- 데이터 정합성과 가용성 제공
- 복제 및 cluster의 재배치도 RADOS Layer를 통해 이루어짐
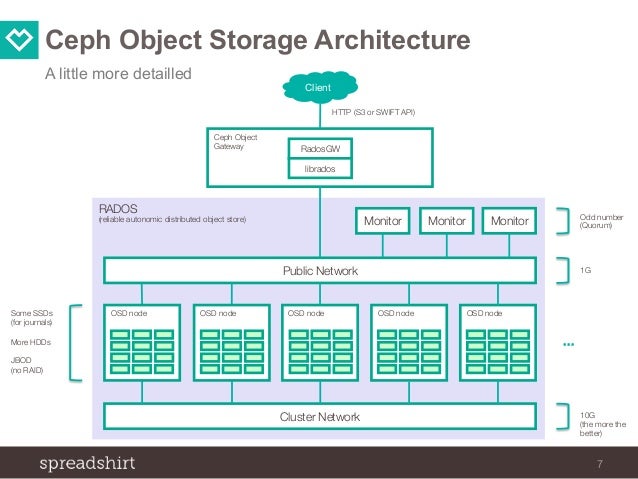
(reference : https://www.slideshare.net/jenshadlich/ceph-object-storage-at-spreadshirt-july-2015-ceph-berlin-meetup)
참고로 위에 링크된 이미지를 참고하면 좀더 RADOS Layer 및 각 구성요소(OSD,MON)에 대한 개념을 잡기가 쉬울것이다.
RADOS(Reliable Autonomic Distributed Object Store)
- RADOS 의미
- Reliable : 복제를 통해 데이터 분실을 회피한다.
- Autonomic : 서로 통신하여 failure를 감지하고 투명한 복제를 수행
- Distributed : 분산된
- Object Store : 객체 저장
- Ceph의 기반이며 모든 것들은 RADOS내에 저장된다.
- Ceph의 중요한 기능을 제공한다.(분산 오브젝트 저장, HA, 신뢰성, no SPOF, self healing, self managing 등)
- CRUSH 알고리즘을 포함한다.
- 모든 Data는 RADOS를 거쳐 object로 저장하게 된다.
- 데이터 타입을 구분하지 않는다.(즉, object, block, file 등을 구분하지 않고 최종 object로 저장한다.)
- object chunk는 4MB 이다.
Hardware Recommendation
연결 방식
- librados : C/C++/Python/Ruby 등이 사용가능하며 TCP/IP 통신을 기반한 raw socket를 사용하여 통신이 이루어진다. HTTP를 사용하지 않고 direct로 연결이 되기 때문에 HTTP overhead를 가지지 않는다.
- 실제 librados를 통해 연결되는 방식은 다음과 같다.
import rados
cluster = rados.Rados(conffile='ceph.conf')
cluster.connect()
cluster_stats = cluster.get_cluster_stats()- RadosGW : Rest (혹은 S3, Swift 등) interface 를 통해 Rados cluster 에 object를 저장한다.
- RBD : Block Storage로 다음과 같은 기능을 제공한다.
- RADOS에서 disk image의 저장소
- Host로부터 VM들을 분리한다.
- object block size는 기본이 4M이고 4k부터 32M까지 설정이 가능하다.
(http://docs.ceph.com/docs/kraken/man/8/rbd/) - kernel module을 2.6.39부터 공식 지원한다.
- CephFS : RADOS내에 존재하는 metadata 서버를 연결하여 file 정보를 확인한후 연결을 수행한다.
참고
구성요소
- OSD : Object Storage Daemon
- HDD나 SSD에 데이터를 저장
- disk 하나당 OSD 하나가 할당되는 개념이다. (물론 변칙으로 다르게 할당은 가능하다.)
- 무결성과 성능을 위한 journal을 사용한다.
- Cluster내에 10 - 1000s OSD를 사용할수 있다.
- 각 object에 대한 저장소 연결을 직접 수행한다.
- osd daemon은 data 재분배의 역할도 수행한다. (object가 최소 2개이상이어야 하나 1개만 존재하는 경우)
- heartbeat을 주고받고 monitor에 failure OSD를 report 한다.
아래 캡처화면은 Red Hat ceph 2 version에서 언급한 OSD와 MON이 동일 host에서 동작할수 있으나 권장은 아니다라는 이야기 이다.

- MON : Monitor
- Monitor는 paxos protocol의 검증사용하기에 quorum 이상의 monitor가 동작해야 한다.
- ceph cluster 당 1개의 monitor가 존재해도 되지만 3개 이상의 monitor를 권장한다. (실제로는 3~7개)
- crush map 및 cluster map을 client에게 전달한다.
- monitor는 저장되는 데이터는 존재하지 않고 cluster map을 소유하고 client로부터의 request가 발생되면
cluster map을 전달하는 역할을 수행한다. 또한 주기적으로 lightweight 한 monitor daemon과 정보를 교환한다.
OSD heartbeat
각 OSD는 서로간에 heartbeat을 주고(default 6초) 받는다. 20초간 heartbeat를 받지 못하는 경우 해당 OSD에
대해서 monitor에게 report 한다. 다수의 OSD가 down되었다고 report를 하는 경우 Monitor는 down 되었다고
report 된 OSD를 down으로 mark 한다.
- MGR : Manager
- 실시간 metric들의 취합(throughput, disk 사용율등 ..)
- 관리기능의 추가(pluggable)기능 제공 (ex. prometheus, restful, custom하게 직접 개발한 모듈 등 )
- 하나의 manager만 동작되어도 되고 1개 이상일 경우 active-standby로 동작된다.
- MDS : metadata
- CephFS에서 사용하는 metadata server이다.
(즉, rbd 형태의 block storage 형태로 사용하는 경우는 불필요하다.)
- CephFS에서 사용하는 metadata server이다.
주요 알고리즘
Ceph의 경우 기존 Storage에의 HW에서 수행되던 (예를 들어 storage controller 같은) 부분을 software 적으로 처리하다보니 그에 맞는 다양한 알고리즘들이 사용되게 된다. 하여 해당 부분을 인지하고 Ceph를 사용하는것이 필수적이다.
우선 ceph의 경우 metadata 서버나 storage 서버에서 직접 계산하는 방식이 아닌 client에서 policy기반으로 계산을 하여 object의 위치를 탐색한다. 해당하는 알고리즘이 CRUSH 알고리즘이다.
CRUSH (Controlled Replication Under Scalable Hashing)
- 클러스터내에 object의 지능적인 분산 작업을 수행한다.
- RADOS에서 사용하는 알고리즘으로 object의 위치를 계산을 통해 결정한다.
- 계산된 데이터 저장소에 의해 어떻게 데이터를 저장하고 가져올지 결정하는 알고리즘
- ceph client는 중앙에 서버나 브로커를 통하기보다 직접 OSD와 통신한다.
- CRUSH는 빠르게 계산이 되고 lookup 과정이 없다. 또한 input이 output에 영향을 미치고 결과가 변하지 않는다.
- ruleset
- pool에 할당되고 ceph client가 데이터를 저장하거나 가져갈때 CRUSH ruleset를 확인한다.
- object에 대한 PG가 포함된 primary OSD를 식별한다.
- 해당 ruleset은 ceph client가 OSD에 직접 연결하여 데이터의 쓰기/읽기를 하게 한다.
workflow
- PG 할당
- pg = Hash(object name) % num pg
- CRUSH(pg, cluster map, rule) 함수 계산
- 해당 CRUSH를 거치면 OSD.(NUM)이 나옴
- 즉, 저장될 OSD number가 나와 해당 OSD에 저장됨

- Cluster map
- 계층적인 OSD map
- Failure Domain
- Pseudo-Random (유사난수)
참고페이지
주요개념
cluster > pool > PG > object
- cluster
- ceph 배포에 기본이다.
- default 는 ceph로 create 된다.
- 다수의 cluster를 생성할수도 있다.
(만약 cluster를 다수 생성하는 경우라면 cluster 에 적절한 port를 설정하여 conflict이 발생되지 않도록 한다.) - http://docs.ceph.com/docs/master/rados/deployment/ceph-deploy-new/
- pool
- Pool은 Ceph의 논리적 파티션을 의미한다.
- 데이터 타입에 따른 Pool을 생성할 수 있다. (예를 들어 block devices, object gateways 등)
- pool 마다 pg 갯수 / replica 갯수를 지정할 수 있다.
즉, pool마다 복제될 object 갯수를 지정할 수 있다. - pool type : replication, Erasure Code 이렇게 두개의 방식이 사용된다.
- placement group(PG)
- exabyte scale의 storage cluster에서는 몇백만개, 그이상의 object가 존재할지 모른다.
이러한 환경에서의 관리가 어렵기에 pg를 두어 pool의 조각을 만든다. - 만약 cluster size보다 상대적으로 적은 PG를 가질 경우 PG마다 너무 많은 data를 가지게 되어
좋은 성능을 낼수 없다. - pool에 대한 pg의 갯수는 다음의 공식을 사용해 계산한다.
(osds X 100) / replicas = (ceph osd stat X 100) / ceph osd pool get \[pool\_name\] size
- exabyte scale의 storage cluster에서는 몇백만개, 그이상의 object가 존재할지 모른다.
NOTE
아래 링크를 한번 읽어보기를 추천한다. pg가 어떤식으로 동작되고 왜 적정한 갯수 지정이 필요한지를 이해할 수 있다.
- object
- 실제 OSD에 저장되는 data이다.
- ID + binary data + metadata (key/value)
실제 데이터를 저장하고 가져오는 일련의 과정
Client는 최초 Monitor와 Cluster Map을 요청하여 전달받고 Cluster Map에 요청하려 했던 DATA의 위치를 확인하고 해당 OSD와 직접 연결을 수행하여 데이터에 대한 Operation을 수행한다.
- ceph client는 ceph monitor에 접속하여 최신의 cluster map을 가져온다.
(cluster map은 node의 up/down 상태정보를 가지고 있다.) - ceph client는 cluster map을 cache하고 업데이트가 가능한 경우 새로운 map을 가져온다.
- ceph client에서는 data를 object/pool id가 포함된 object로 변환한다.
- ceph client에서는 CRUSH algorithm을 사용해 PG와 Primary OSD를 결정한다.
- ceph client는 primary OSD를 연결하여 data를 직접 저장하고 가져온다.
(client에서 OSD에 직접 data를 쓴다.) - Primary OSD는 Crush Lookup을 실행하여 secondary PGs와 OSD를 결정한다.
- replicate pool에서는 primary OSD는 secondary OSD들에 data를 전송하고 object를 복사한다.
- erasure coding pool에서는 primary OSD는 object를 chunk로 분할하고 chunk들을 encode 하여 secondary OSD들에 writing 한다.
개인적으로 정리한 내용을 아래와 같은 diagram으로 표현해보았다.

Object 의 정보
아래 command를 통해 object 대한 정보를 확인할 수 있다.

- OSD map version
- pool name
- pool ID
- object name
- placement group ID (object 가 속한)
- OSD 5,6 번에 속해 있고 현재 UP
- OSD 5,6 번에 속해 있고 현재 동작중
Ceph Hardware
Network
- public network : client 및 monitor, osd와의 연결등에 사용
- cluster network : heartbeat, object의 복제와 복구 traffic
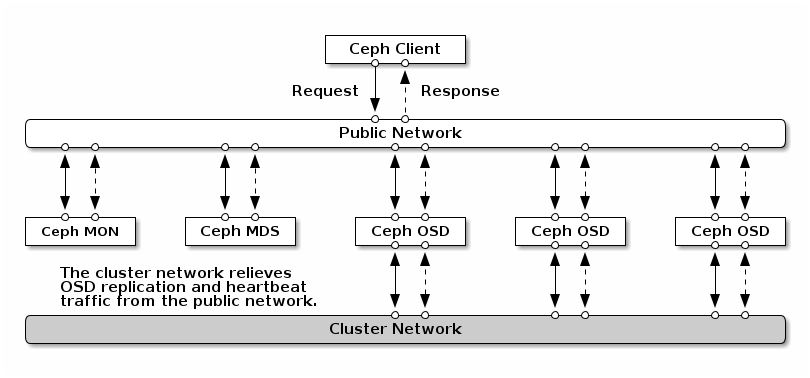
H/W 선정
CPU/Memory/Disk 선정에 대한 가이드가 아래 링크에 나와있다.
(구성하려는 목적에 따라 적절한 비용산출이 함께 이루어져야 하기에 해당 링크를 토대로 H/W 산정을 상세히 진행할 필요가 있다.)
Ceph의 간단한 사용법
client에서 Ceph로 접근 방법
아래 방식들로 접근을 위해서는 다음과 같은 파일이 필요하다.
/etc/ceph/ceph.conf
/etc/ceph/ceph.client.admin.keyring해당 파일을 복사해 client로 사용할 서버에 두어야 한다.
또한 아래와 같은 ceph command 를 사용할 수 있는 package를 설치해야 한다.
# CentOS 기반
yum install ceph-common -y 참고정보
- cache-tiering
journal의 경우 write를 빠르고 일관성있게 해주는데 비해 read 에 대해서는 무엇도 도움이 되지는 않는다.
cache-tiering의 경우 read 대한 cache를 수행하게 한다. - iscsi : 차후작성
- NFS : 차후작성
- BlueStore
기존 FileStore의 단점이 journaling of journal을 보완하여 raw device에 직접 기록하는 storage backend. - HCI (OpenStack with Ceph)
- NUMA Pinning 과 cpu/memory의 할당비율을 지정해야 한다.
설치방법
- http://mr100do.tistory.com/655 (작성중)
- Kubernetes 기반에 Ceph를 운영하는 Rook : https://mr100do.tistory.com/1102
참고사이트
- http://www.sparkmycloud.com/blog/ceph-internals-and-integration-with-openstack/
- https://www.anchor.com.au/blog/2012/09/a-crash-course-in-ceph/
- https://www.virtualtothecore.com/en/adventures-ceph-storage-part-1-introduction/
- https://access.redhat.com/documentation/en-US/Red_Hat_Ceph_Storage/2/pdf/Architecture_Guide/Red_Hat_Ceph_Storage-2-Architecture_Guide-en-US.pdf
- http://www.webstorage.co.kr/2017/01/12/cephrbd%EC%9D%98_%EA%B5%AC%EC%A1%B0_%EB%B6%84%EC%84%9D%EA%B3%BC_ceph%EC%97%90%EC%84%9C%EC%9D%98_%EC%A0%80%EC%9E%A5%ED%98%95%ED%83%9C/
- https://fajlinux.com/cloud/ceph-an-overview/
'Storage > System&Tools' 카테고리의 다른 글
| Object Gateway with radosgw (0) | 2020.11.29 |
|---|---|
| Ceph benchmark Test (0) | 2020.10.13 |
| Ceph-csi (0) | 2020.04.21 |
- Total
- Today
- Yesterday
- Jenkinsfile
- hashicorp boundary
- macvlan
- jenkins
- OpenStack
- vmware openstack
- wsl2
- openstack backup
- K3S
- azure policy
- minikube
- ceph
- DevSecOps
- openstacksdk
- socket
- aquasecurity
- ansible
- Terraform
- nginx-ingress
- kata container
- open policy agent
- mattermost
- kubernetes
- metallb
- kubernetes install
- GateKeeper
- crashloopbackoff
- boundary ssh
- minio
- Helm Chart
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |